What is a Tidyverse-centric approach?
I describe my Fundamentals of R course as taking a "Tidyverse-centric approach." If you're new to R, you might be wondering what the heck I'm talking about. Here's my explanation as to what the Tidyverse is and why I use it to teach R.
The Tidyverse is described as:
... an opinionated collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures.
The Tidyverse consists of multiple packages. When you run the code library(tidyverse), you are actually loading multiple packages, including:
readr to import data
dplyr for data wrangling and analysis
ggplot2, which is far and away the most popular package for data visualization
These packages all work together in a consistent way. One thing that ties most of them together is what's called the "pipe."

The pipe allows you to chain together a series of functions to conduct a series of manipulations on it

We start with our data. Then we do step1. Then we do step2. Then we do step3. The pipe ties it all together, enabling us to multiple things to our data, all in one step.
Actual tidyverse code might look something like this:
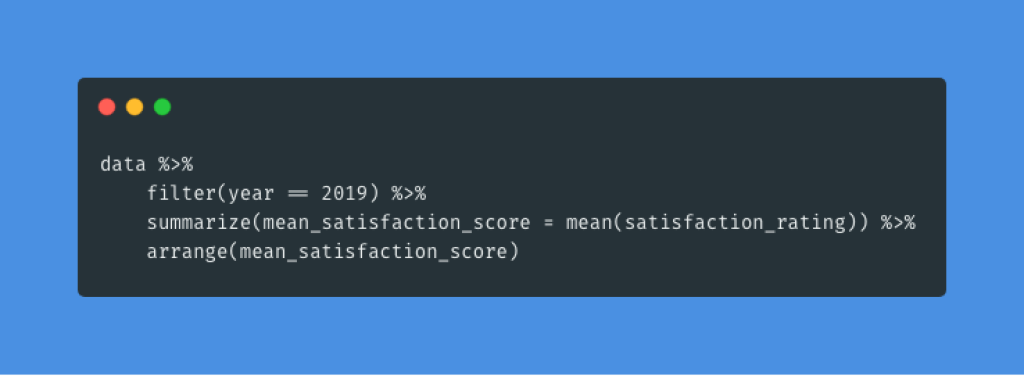
You can almost read this code in English.
Start with our data.
Filter to only include observations from 2019.
Calculate a mean satisfaction score from all individual observations of the satisfaction ratings.
Arrange our results by the mean satisfaction score.
Being able to read the code is one of the unique features of the Tidyverse. The Tidyverse manifesto prioritizes software that is designed
... primarily so that it is easy to use by humans. Computer efficiency is a secondary concern because the bottleneck in most data analysis is thinking time, not computing time.
The emphasis on human-readable function names (filter, summarize, arrange, etc.) is one part of this. The use of the pipe is another. Think of breaking code into multiple lines using the pipe as the equivalent of using spaces to make words easier to use.
Youcanwriteasentencewithoutspacesbetweenwordsbutitsureisn'teasytoreadamirite?
Did you enjoy that? Then you'll especially enjoy reading base R code, which often looks like this:

And note, this does the same thing as my piped version above, minus the arrange step. Even with one fewer step, it's already much less readable.
For me, learning about the Tidyverse was when I finally "got" R. I'm far from the only one. In their My R Journey pieces, Dana Wanzer and Rika Gorn said similar things. By focusing on humans first, the Tidyverse makes it easier for newcomers to learn R. It's why I teach R exclusively using the Tidyverse.
Perhaps you're worried that this is an idiosyncratic approach to R that isn't widely embraced. Far from it. University of Missouri journalism professor Mike Kearney's recent analysis shows that Tidyverse packages are among the most downloaded of all R packages.
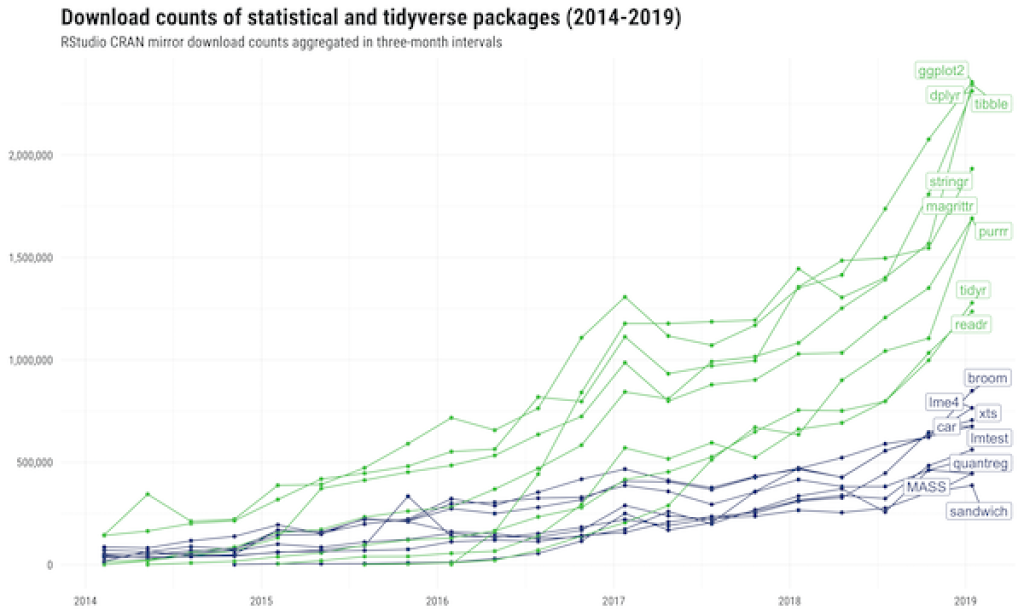
Kearney draws two main lessons from the plot:
First, that a lot of people use (and therefore test, troubleshoot, and write documentation for) tidyverse packages. Second, that use of tidyverse packages is not merely a fad or momentary trend. Indeed, compared to widely used statistical packages, there is a considerably higher download rate among tidyverse packages (even above and beyond the general uptick in overall R usage).
Learning using a Tidyverse-centric approach is both easier to learn starting out (something that data scientist David Robinson had to argue for two years ago, but which is now widely accepted) and sets you up to join a huge community of users following a similar approach.
Sign up for the newsletter
Get blog posts like this delivered straight to your inbox.

You need to be signed-in to comment on this post. Login.