Tidy Data
This lesson is called Tidy Data, part of the R in 3 Months (Fall 2022) course. This lesson is called Tidy Data, part of the R in 3 Months (Fall 2022) course.
Transcript
Click on the transcript to go to that point in the video. Please note that transcripts are auto generated and may contain minor inaccuracies.
Loading transcript...
Your Turn
Read the Tidy Data vignette
Take a look at your data and see which principles of tidy data it violates
Learn More
In the video, I only talk about two types of data tidying: each variable forming a column and each type of observational unit forming a table. If you want to see examples of the third type (each observation forming a row), check out the tidy data vignette from the tidyr package.
The workflow diagram I talked about is from Chapter 1 of R for Data Science.
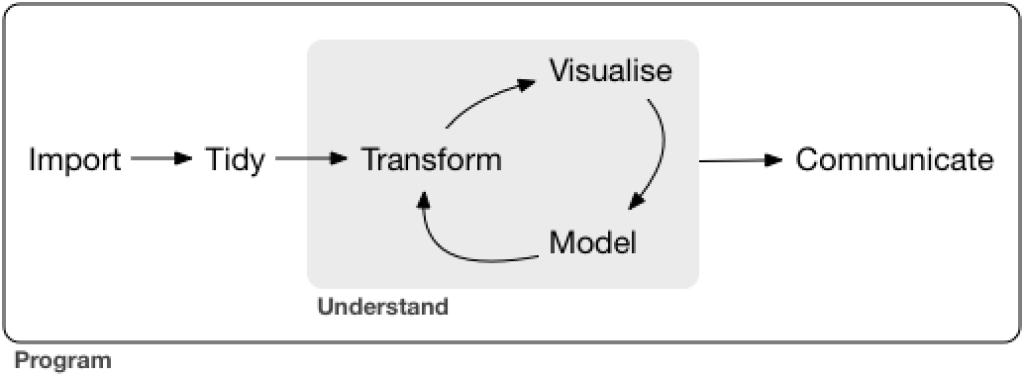
One small note unrelated to the main content of this lesson: I recorded it before dplyr 1.0 was released. If you have this version of dplyr installed, you have access to the across() function, which enables you to do summaries across rows. My example of finding it challenging to summarize German speakers data across rows would be much easier using the across() function. However, I still think that in most cases, it is easier to tidy your data and work with it in that format.
Have any questions? Put them below and we will help you out!
Course Content
142 Lessons
You need to be signed-in to comment on this post. Login.
Vuk Sekicki • April 19, 2021
Hello David,
Could you help me out understanding this: names_pattern = "(.)(.+)"
Specifically what is "(.)(.+)"
Thanks.
Matt M • November 9, 2021
I see you re-worded the 3 rules of tidy data from the vignette. Although I think I understand conceptually what is being sought, I'm not sure I follow what each rule means (i.e., what I need to do to make sure that I'm complying with the rule) and what a violation of each rule looks like (the third rule in particular)